
How I work (mostly) TDD-style
A wild TDD flowchart has appeared! On Twitter.
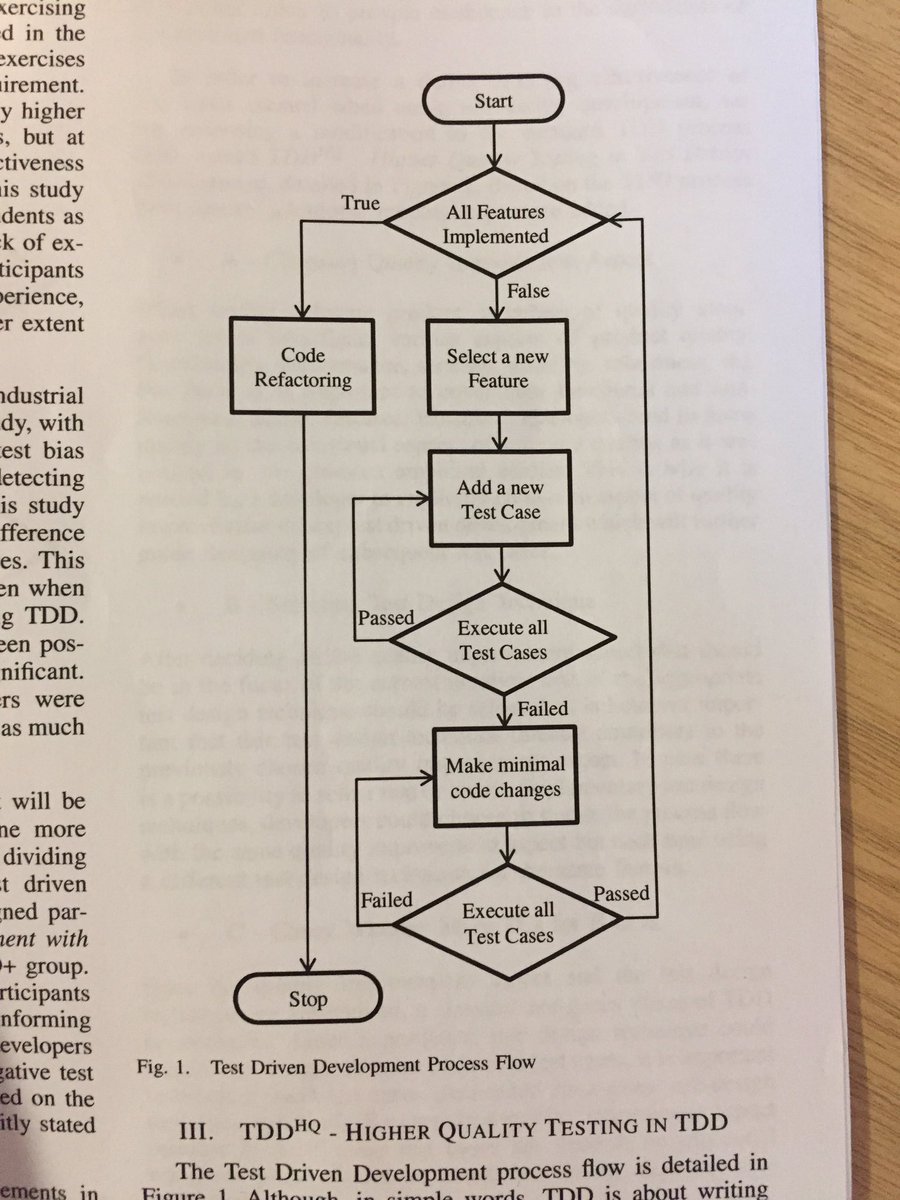
This thing is weird in a number of ways.
First and perhaps worst, it has you refactor only after all features are implemented. This is, of course, way too late. The “official” TDD cycle has us refactor every time the tests go Green.
Second, it seems to say that you select a new feature, write one test case, and when it passes, select a new feature. I’d have imagined that one would need more than one test case per feature. I slice features pretty thin and I almost always need more than one.
I found a PDF of the article. Pardon a brief delay while I read it.
Hi, here I am again. After I abstract out all the pseudo-science of basing conclusions on 22 college students, and the strong likelihood that the authors don’t actually understand what TDD is, and the good chance of confirmation bias having sneaked in somewhere, I’d interpret the results of this tiny experiment this way:
- Using more varieties of tests is likely to find more bugs than using fewer varieties;
- TDD alone is probably not enough for robust testing of a complex program.
- Instructing students to use many ways of testing probably delivers better results than telling them to use only one kind of test.
You can draw your own conclusions, and you should. I’ll just say here that all the development-focused Agilistas I know recommend acceptance-level tests as well as the smaller-scale TDD tests. See Programmer Tests and Customer Tests in classic XP. Agilistas also recommend “sapient” exploratory testing by people with strong testing skills.
I believe that if a Customer Test fails, or a defect is found, we can always think of a valid Programmer Test that is missing or wrong. I believe, in other words, that every defect in a program can be, and should be, detected by a low-level test of a single object or a very small number of collaborating objects. (I’m wrong in this belief and I can prove it, but it’s the way to bet.)
So this paper, somewhat weak in my opinion, has “discovered” what we’ve been saying for twenty years. Woot! But that’s not why I’m here.
A number of people have already written about how they TDD, in response to this article or to each other. I’ll try to footnote1 some links to those ideas. Here, I plan to describe how I develop code, with TDD a key part of what I do.
What follows is even more complex than the description will seem. That’s because software development, even with TDD, is complex. Think of it this way:
The big picture …
With TDD, the code grows around a simple framework of Red / Green / Refactor.
What really goes on is continuous thinking, experimenting, wandering, learning, trying.
This all spirals around the basic framework like an elaborate flowering vine.
TDD is just a simple framework.
Yet as we work using that framework, what we actually do reflects the endlessly rich and complex process of creating something new.

In some detail …
Here’s roughly what I do when I set out to develop something, be it an entire program or a single feature. Here, we’re mostly thinking about a single feature in a program I’ve been working on. Imagine that you and I are pairing on something. Here’s what might happen
Let’s think a lot … hey, lets even think all the time!
I think a lot even when I’m not at my computer. I imagine “algorithms” for doing whatever the thing is. My thoughts at this level usually consider aggregates of information, tables or lists or sets, and what are today called “map-reduce” kinds of operations. (To me, they’re probably more set-theoretic but that problem is due to youthful indiscretions that need not concern us here.) Essentially, I’m thinking about the information I have, and how I can transform it into the information I want.
So as we pair, we talk about what we’re up to, what we might do, what objects might apply. When I’m alone, I think about those things and try not to talk out loud, lest the other people in the coffee shop become concerned.
I think a lot, and I recommend the practice to everyone.
Let’s explore and learn about things …
Very often, there’s some system object that we need to learn about to build our feature. Maybe it’s in the base libraries or some library that we use, or could use. Maybe it’s in our own code base, but we don’t remember much about it. So we need to learn about it. In a word, we’re experimenting.
Perhaps we’ll go into an interactive tool like IRB, or work in a sandbox or workspace. We’ll type in statements and look at what they print out. We’re learning how the objects work, what they like to hear, what they say in reply.
Maybe we’ll write a little program in a file, with print statements in it, run it and see what it prints. We’ll change the inputs, and run again.
Personally, I prefer little programs over using the sandbox approach when the chunk of code I need is more than a couple of statements. YMMV, and as we work together we’ll do both.
Maybe we’ll create a new test class, and put test cases into it, much like the cases we’d use in a sandbox or file.
Personally, I try to remember to put assert statements in these but sometimes I still just print things out. What I’m doing in this case is building something to save. The test cases can be used later to remind me how this object works. Using asserts works better, because it records the learning in the test, so I hope you help me remember to do this as we pair.
Of course, we need less of all this if the objects in question are already in the system and have useful low level tests. Lesson to learn here: write low level tests. We, or someone like us, will be back later, all full of ignorance.
Let’s experiment, and test, and design …
All this time, we’re thinking about how the objects we’re looking at can be used to solve the problem I’m here to solve. We shape my experiments dynamically. We try something, learn something (for me, I usually learn that I’m wrong), we re-align, try something else. We’re finding my way through a maze of twisty little passages, all different.
This is testing. It’s inquiry. Some of it is a lot like TDD, in that we have some behavior in mind to learn about, with intention to use it, and we write a test and run the test. We refine what we’re doing as we go.
Thinking all the time: I still recommend this. Pretty serious about it, actually.
Let’s zero in, finally, on the actual feature …
Sooner or later, we’ve learned a bit and feel ready to get down to work, turning our attention back to the feature we were here to implement. Now, I want to say that we were always working on that feature. We’re learning how to do it. Some of that learning goes into our heads, some gets documented in tests.
Some of what we learn will be used, and sometimes, for me, I’ve mostly learned “don’t do that”. That’s good, too.
Let’s lean toward more tests. More tests, more learning.
In the future, I expect to find that I wish we had done more of this with real, running tests, but here in the past, I’m sometimes too hungry to try something to get it documented in a test.
When I’m at my best, you can slow me down, and we set out to create a new TestCase, or begin to extend an existing one. Let’s assume you managed that this time.
First, we usually run our tests to be sure that they all still run. If they don’t, we fall out of this process, because our code management and saving process has failed somehow. We figure out what’s up, and get to all Green on the tests. Now, sometimes I forget to run the tests first to get all Green. Usually this doesn’t bite me. Sometimes it does. Hey, life’s tuff. That’s why I need a pair whenever possible. Maybe you do, too.
It might sometimes happen that I want to stop working while we’re Red,maybe so that we can start on Red later. One case, for example, is when I use the trick of leaving a test Red so I’ll remember what I was working on. Still, I don’t do that very often at all. I like to leave the machine Green, and I’d likely even revert to get back to Green if I had to. When we work together, let’s try to stay Green, OK?
We write a small test (Arrange, Act, Assert, with Assert written first most times). What we’re doing here is designing. We’re writing down our ideas about how the object we’re creating is used. Because we write a test, we become the first real user of the object, and we experience how good – or how bad – its interface really is.
Once it’s written, we verify that the test fails. If it doesn’t, we have something to learn. Sometimes the test is bad. Sometimes, rarely, we’ve already built the feature and forgot. We treat a failure to fail as something that needs a hard look.
Now, often, I forget to watch the test fail. I’m sure it will, so I just go ahead and move to the coding step below. When you catch me doing this, please correct me. It’s not often the case that the test won’t fail, but when it does, it’s important.
Let’s write a little code …
Now, we write as little code as we can to make the single failing test pass. Things seem to go better when we pick a very small step forward and write very small code to take that step.
Personally, I find this difficult to do, sometimes, as I have some kind of p-baked2 whole algorithm in mind, so often I write more code than is absolutely necessary. That said, I do pretty well at writing only a tiny bit of code, so I’m not going to beat myself up over doing a bit too much sometimes.
Besides, if I write too much code, making it work will take too long and too many red bars, and I’ll learn fairly soon that I’ve bitten off too much. I revert and go back to smaller steps. Well, I say “fairly soon”. I think I’d do well to have a five- or ten-minute timer to alert me when the tests haven’t gone Green for that long. Twenty minutes and I’m clearly in trouble. Help me, pair-partner, you’re my only hope.3
When the test passes, I usually have the next step in mind. Probably you’re the same. I try always to remember to look at the code and clean it up. Sometimes I defer that decision. In the future, I almost always find that deferring cleanup was not my best idea. But I still do it: I think I’m hungry for green bars or something. So help me remember that refactoring step, OK?
After the (possibly null) refactoring, we probably have another test already in mind. We’ve done this one little thing, but we likely have the whole “algorithm” and least somewhat in mind and usually we see what little bite to take next. Now I’m not perfect and sometimes I don’t see a small bite and I take a larger one. If I’m pairing, I always chat with my colleague about what we should do next. I hope you’ll help keep the steps small, it seems to work better.
Of course, if we’re pairing, we’re talking all the time, about the code, about what we’re doing, about how the hell does the FTP class really work, about what its like to have a stent jammed into your heart, about what kind of car I should get next, about what the cat did … but mostly about what we’re trying to do and how to do it.
When things are good, let’s cycle back …
When the test runs, we loop back to somewhere in this description. Most commonly, our feature isn’t “done” according to our understanding of what we’re doing. In a real job situation, there would probably also be Customer Tests that don’t work yet. Otherwise, we just talk about it and decide if we’re done.
Often, we decide that we’re done in a surprising new way. For example, right in the middle of things on the iPad project I’ve been writing about, we realized that what we had could be used to publish, not just my iPad articles, if I ever write that way, but all my articles. We redefined our “product” in the light of this discovery. So the next feature may not be at all like the one we’d have said was next at the beginning of the session.
This is that darn “thinking” again. We’re not building things from a fixed list. We’re dynamically choosing the best thing to do next as we go. Some might say this is “agile”. I’d just say it seems to make sense.
This seems awfully chaotic, Ron
Wait, isn’t TDD just Red, Green, Refactor? Isn’t it at least a simple flowchart like that one at the top of the page?
Well, yes and no. Let me say clearly that I think I’d do better if I always did the write a test make it run refactor thing more consistently. I say that because so often, when I just plunge in, I get in trouble. And when I come back to the code later, if there are tests I can get going far more quickly than if there aren’t. There are two issues I’d like to call out, though:
First, and smallest: sometimes, strict TDD seems to get in my way. My thoughts are so ill-formed that I can’t even yet imagine a test – or it seems that I can’t. It feels like creating a test case, writing a test, blah blah takes too long, can’t we just get down to it and call the Dir.glob() and see what the heck it does?
More important is this: look at this picture again:
Sticking to the TDD framework is the best thing I know, even though I don’t always manage to do it. I wish I did and I’m happy to be held to the practice by whoever is working with me.
Even within that framework, there’s a lot more going on. Some folks, in the spirit of “Shu Ha Ri”, will try to hold beginners very strictly to the framework. And I think that sticking to the ritual will help a beginner or an oldbie. But even inside the framework, we must think, as much and as well as we can.
Programming is a process of learning. We have vast structures in our heads, and in our code, and we’re finding our way around them, following the twisty paths, creating new ones, and removing old ones.
Programming is a thought-driven process. TDD can help us with that process but it cannot replace that process. TDD is a framework for thinking and we need to apply all the thinking we know how to do as we work within that framework.
So, yeah
TDD isn’t like that flowchart at the top. It’d not just Red, Green, Refactor, either. It’s like the parallel bars, or the rings, or the ice rink. It’s what you do with them that counts. It’s what you do with TDD that counts.
-
Here are some links to related articles: Jon Reid; Bill Caputo; Jan Olbrich. ↩
-
You know about half-baked ideas, I’m sure. P-baked ideas are like that, usually for very small values of p. ↩
-
Maybe someone to flap my head with a pig’s bladder when it’s time for me to think. ↩